
با هیاهوی فعلی پیرامون هوش مصنوعی (AI)، به راحتی می توان فرض کرد که این یک نوآوری اخیر است. در واقع، هوش مصنوعی بیش از 70 سال است که به این شکل یا آن شکل وجود داشته است. برای درک نسل فعلی ابزارهای هوش مصنوعی و اینکه آنها به کجا می توانند منجر شوند، درک اینکه چگونه به اینجا رسیدیم مفید است.
هر نسل از ابزارهای هوش مصنوعی را میتوان بهعنوان یک پیشرفت نسبت به نسلهای قبلی دید، اما هیچکدام از ابزارها بر آگاهی متمرکز نیستند.
آلن تورینگ، ریاضیدان و پیشگام کامپیوتر مقاله ای در سال 1950 منتشر کرد با جمله آغازین: “پیشنهاد می کنم به این سوال توجه کنیم که آیا ماشین ها می توانند فکر کنند؟” او در ادامه چیزی به نام «بازی تقلید» را پیشنهاد میکند که امروزه معمولاً به آن آزمون تورینگ میگویند، که در آن ماشینی هوشمند در نظر گرفته میشود که نتوان آن را از یک انسان در مکالمه کور تشخیص داد.
پنج سال بعد اولین استفاده از عبارت “هوش مصنوعی” منتشر شد. در یک پیشنهاد برای پروژه تحقیقاتی تابستانی هوش مصنوعی در دارتموث.
از همان ابتدا، شاخه ای از هوش مصنوعی که به سیستم های خبره معروف شد از دهه 1960 به بعد توسعه یافت. این سیستم ها برای جذب تخصص انسان در زمینه های تخصصی طراحی شده اند. آنها از بازنمایی واضح دانش استفاده کردند و بنابراین نمونه ای از آنچه که هوش مصنوعی نمادین نامیده می شود.
موفقیتهای اولیه بسیاری از جمله سیستمهایی برای شناسایی مولکولهای آلی، تشخیص عفونتهای خونی و جستجوی مواد معدنی وجود داشت. یکی از تاثیرگذارترین نمونه ها این بود سیستمی به نام R1 که در سال 1982 با طراحی پیکربندیهای کارآمد سیستمهای کامپیوتری کوچک خود، سالانه 25 میلیون دلار صرفهجویی کرد.
مزیت کلیدی سیستم های خبره این بود که یک متخصص موضوعی بدون تجربه برنامه نویسی اصولاً می تواند یک پایگاه دانش کامپیوتری ایجاد و حفظ کند. یک جزء نرم افزاری که به عنوان موتور استنتاج شناخته می شود، سپس این دانش را برای حل مسائل جدید در حوزه موضوعی، با دنباله ای از شواهد که شکلی از توضیح را ارائه می دهد، به کار می گیرد.
آنها در دهه 1980 بسیار خشمگین بودند، زیرا سازمانها برای ایجاد سیستمهای خبره خود فشار آوردند، و امروزه نیز بخشی مفید از هوش مصنوعی هستند.
وارد یادگیری ماشین شوید
مغز انسان شامل حدود 100 میلیارد سلول عصبی یا نورون است که توسط یک ساختار دندریتی (شاخه ای) به یکدیگر متصل شده اند. بنابراین در حالی که هدف سیستمهای خبره مدلسازی شناخت انسان بود، حوزه جداگانهای به نام پیوندگرایی نیز در حال ظهور بود که هدف آن مدلسازی مغز انسان به روشی واقعیتر بود. در سال 1943 دو محقق به نام های وارن مک کالوچ و والتر پیتس یک مدل ریاضی برای نورون ها ایجاد کرده استکه در آن هر یک بسته به ورودی های خود یک خروجی باینری تولید می کند.
بیشتر بخوانید:
به زودی درک هوش مصنوعی برای انسان غیرممکن خواهد شد – تاریخچه شبکه های عصبی دلیل آن را به ما می گوید
یکی از اولین پیاده سازی های کامپیوتری نورون های متصل توسط برنارد ویترو و تد هاف در سال 1960 توسعه یافت. چنین پیشرفتهایی جالب بودند، اما تا زمانی که الگوریتم آموزش مدل نرمافزاری به نام توسعه یافت، کاربرد عملی محدودی داشتند پرسپترون چند لایه (MLP) در سال 1986
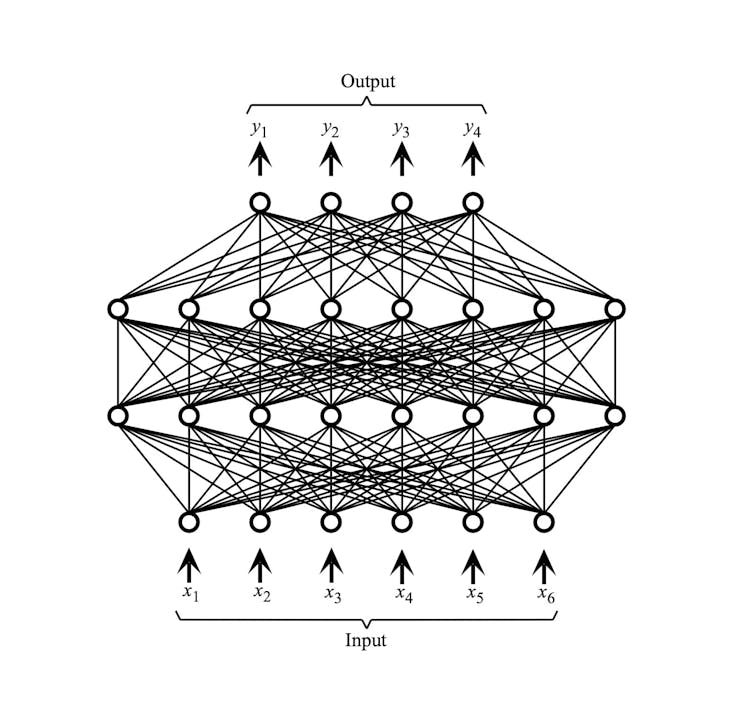
آدریان هاپگود، اعتبار (بدون استفاده مجدد)
یک MLP آرایشی از سه یا چهار لایه از نورون های شبیه سازی شده ساده است که در آن هر لایه به طور کامل به لایه بعدی متصل است. الگوریتم یادگیری برای MLP یک پیشرفت بود. این اولین ابزار عملی را فعال می کند که می تواند از مجموعه ای از مثال ها (داده های آموزشی) یاد بگیرد و سپس تعمیم دهد تا بتواند داده های ورودی قبلا دیده نشده (داده های آزمایشی) را طبقه بندی کند.
این امر با اتصال وزنهای عددی به اتصالات بین نورونها و تنظیم آنها برای به دست آوردن بهترین طبقهبندی با دادههای آموزشی قبل از استفاده از آن برای طبقهبندی نمونههایی که قبلاً دیده نشده بود، به دست آورد.
MLP میتواند طیف گستردهای از کاربردهای عملی را انجام دهد، مشروط بر اینکه دادهها در قالبی نمایش داده شوند که میتواند از آن استفاده کند. یک مثال کلاسیک، تشخیص دست خط بود، اما تنها در صورتی که تصاویر از قبل پردازش شده باشند تا ویژگی های کلیدی را انتخاب کنند.
مدل های جدیدتر هوش مصنوعی
پس از موفقیت MLP، بسیاری از اشکال جایگزین از شبکه های عصبی شروع به ظهور کردند. مهم بود شبکه عصبی کانولوشنال (CNN) در سال 1998، که شبیه MLP بود، به جز لایههای اضافی نورونها برای شناسایی ویژگیهای کلیدی تصویر، بنابراین نیاز به پیشپردازش را از بین برد.
هر دو MLP و CNN مدلهای تبعیضآمیز بودند، به این معنی که میتوانستند، معمولاً با طبقهبندی ورودیهای خود، برای تولید تفسیر، تشخیص، پیشبینی یا توصیه تصمیم بگیرند. در همین حال، مدلهای شبکه عصبی دیگری در حال توسعه هستند که مولد هستند، به این معنی که میتوانند پس از آموزش بر روی تعداد زیادی از نمونههای قبلی، چیز جدیدی ایجاد کنند.
شبکههای عصبی مولد میتوانند متن، تصویر یا موسیقی تولید کنند و همچنین توالیهای جدیدی را برای کمک به کشف علمی تولید کنند.
دو مدل شبکه عصبی مولد متمایز شد: شبکه های متخاصم مولد (GAN) و شبکه های ترانسفورماتور GAN ها به نتایج خوبی دست می یابند زیرا تا حدی “متخاصم” هستند، که می تواند به عنوان یک منتقد داخلی دیده شود که به کیفیت بهبود یافته از مولفه “تولید کننده” نیاز دارد.
شبکه های ترانسفورماتور از طریق مدل هایی مانند GPT4 (ترانسفورماتور 4 پیشآموزشی ژنراتور) و نسخه متنی آن ChatGPT. این مدل های زبان بزرگ (LLM) بر روی مجموعه داده های عظیم استخراج شده از اینترنت آموزش می بینند. بازخورد انسانی از طریق به اصطلاح یادگیری تقویتی، عملکرد آنها را بیشتر بهبود می بخشد.
علاوه بر تولید قدرت مولد چشمگیر، مجموعه آموزشی عظیم به این معنی است که چنین شبکه هایی دیگر مانند شبکه های قبلی خود به حوزه های باریک تخصصی محدود نمی شوند، بلکه اکنون برای پوشش هر موضوعی تعمیم داده شده اند.
هوش مصنوعی به کجا می رود؟
قابلیتهای LLM منجر به پیشبینیهای وحشتناکی از تسخیر هوش مصنوعی در جهان شده است. به نظر من چنین ترس آفرینی بی مورد است. در حالی که مدلهای فعلی به وضوح قویتر از مدلهای قبلی خود هستند، مسیر حرکت به سمت ظرفیت، قابلیت اطمینان و دقت بیشتر به جای هر شکلی از آگاهی باقی میماند.
همانطور که پروفسور مایکل وولدریج اشاره کرده است در شهادت مجلس اعیان پارلمان بریتانیا در سال 2017، “رویای هالیوود در مورد ماشین های حساس اجتناب ناپذیر نیست، و من واقعا راهی را نمی بینم که ما را به آنجا برساند”. پس از گذشت هفت سال، ارزیابی او هنوز درست است.
کاربردهای بالقوه مثبت و هیجان انگیز زیادی برای هوش مصنوعی وجود دارد، اما نگاهی به تاریخ نشان می دهد که یادگیری ماشین تنها ابزار نیست. هوش مصنوعی نمادین همچنان نقشی را ایفا می کند، زیرا اجازه می دهد حقایق شناخته شده، درک و دیدگاه های انسانی گنجانده شود.
به عنوان مثال، یک ماشین بدون راننده، می تواند قوانین جاده را به جای اینکه آنها را با مثال یاد بگیرد، یاد بگیرد. یک سیستم تشخیص پزشکی را می توان در برابر دانش پزشکی برای تأیید و توضیح نتایج یک سیستم یادگیری ماشین بررسی کرد.
دانش عمومی را می توان برای فیلتر کردن نتایج توهین آمیز یا مغرضانه به کار برد. آینده روشن است و شامل استفاده از طیف وسیعی از تکنیکهای هوش مصنوعی، از جمله برخی از آنهایی است که سالهاست وجود داشتهاند.